-
[Python] Study on non-linear-regression데이터 분석 2022. 4. 13. 22:39
출처 : https://www.kaggle.com/code/ibrahimbahbah/non-linear-regression-tutorial/notebook
비선형 사용 이유
데이터가 직선을 벗어난 곡선 추세를 보이는 경우 선형 회귀는 비선형 회귀에 비해 정확한 결과를 생성하지 않습니다. 그리하여 사용하는 것이 비선형 회귀입니다.
필수 라이브러리 가져오기
import numpy as np import matplotlib.pyplot as plt %matplotlib inline선형 회귀(Linear-Regression)
선형 함수는 Y = ax + b와 같이 표현합니다.
x = np.arange(-6.0, 6.0, 0.1) # -6 ~ 6 까지 0.1 간격으로 배열 생성 y = 4*(x) + 5 # 데이터 생성 y_noise = 2 * np.random.normal(size=x.size) # x.size(120)개의 평균 0, 표준편차 1의 정규분포에 2를 곱한 오차 생성 ydata = y + y_noise # 데이터 생성 #plt.figure(figsize=(8,6)) plt.plot(x, ydata, 'bo') plt.plot(x,y, 'r') plt.ylabel('Dependent Variable') plt.xlabel('Indepdendent Variable') plt.show()
비선형(Non-Linear-Regression)
다항(Polynomial-Regression)
다항 함수는 Y = ax3 + bx2 + cx + d와 같이 표현합니다.
x = np.arange(-6.0, 6.0, 0.1) y = 1*(x**3) + 4*(x**2) + 2*x + 1 y_noise = 20 * np.random.normal(size=x.size) # x.size(120)개의 평균 0, 표준편차 1의 정규분포에 20을 곱한 오차 생성 ydata = y + y_noise # 데이터 생성 plt.plot(x, ydata, 'bo') plt.plot(x,y, 'r') plt.ylabel('Dependent Variable') plt.xlabel('Indepdendent Variable') plt.show()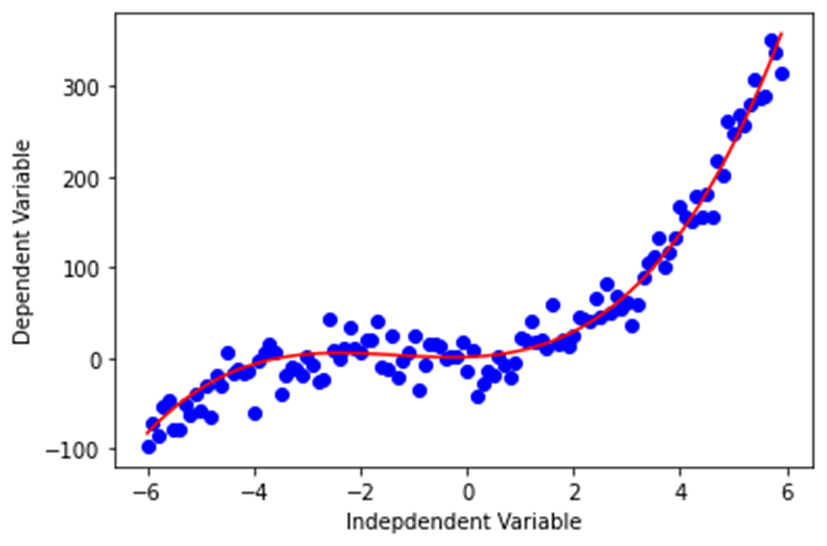
2차(Quafratic-Regression)
2차 함수는 Y = ax2 + b와 같이 표현합니다.
x = np.arange(-6.0, 6.0, 0.1) y = np.power(x,2) y_noise = 2 * np.random.normal(size=x.size) # x.size(120)개의 평균 0, 표준편차 1의 정규분포에 2를 곱한 오차 생성 ydata = y + y_noise plt.figure(figsize=(8,6)) plt.plot(x, ydata, 'bo') plt.plot(x,y, 'r') plt.ylabel('Dependent Variable') plt.xlabel('Indepdendent Variable') plt.show()
지수(exponential function-Regression)
지수 함수는 Y = a + bcx와 같이 표현합니다.
(여기서 b ≠0, c > 0, c ≠1, x는 임의의 실수입니다. 밑수 c는 상수이고 지수 x는 변수입니다.)X = np.arange(-6.0, 6.0, 0.1) Y= np.exp(X) Y_noise = 10 * np.random.normal(size=x.size) # x.size(120)개의 평균 0, 표준편차 1의 정규분포에 10을 곱한 오차 생성 Ydata = Y + Y_noise plt.figure(figsize=(8,6)) plt.plot(X,Ydata,’bo’) plt.plot(X,Y,’r’) plt.ylabel('Dependent Variable') plt.xlabel('Indepdendent Variable') plt.show()
로그(Logarithmic-Regression)
로그 함수는 Y = a * log(x)와 같이 표현합니다.
X = np.arange(1.0, 10.0, 0.1) Y = np.log(X) plt.figure(figsize=(8,6)) plt.plot(X,Y,’r’) plt.ylabel('Dependent Variable') plt.xlabel('Indepdendent Variable') plt.show()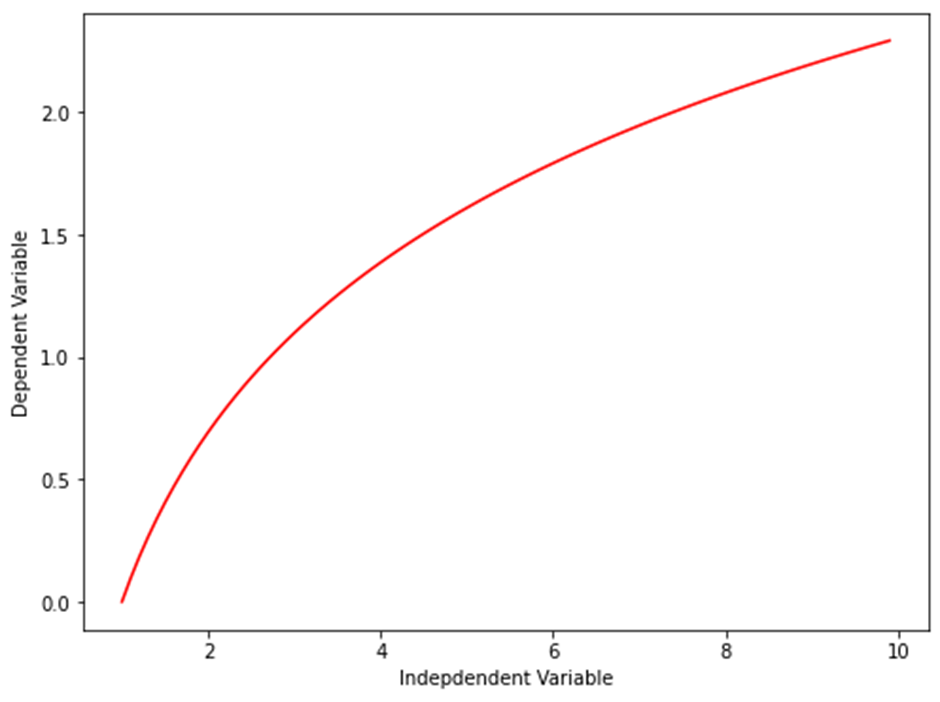
시그모이드/로지스틱(Sigmoidal/Logistic-Regression)
시그모이드/로지스틱 함수는 Y = a+b/1+c(x-d)와 같이 표현합니다.
X = np.arange(-5.0, 5.0, 0.1) Y = 1-7/(1+np.power(5, X-3)) plt.figure(figsize=(8,6)) plt.plot(X,Y) plt.ylabel('Dependent Variable') plt.xlabel('Indepdendent Variable') plt.show()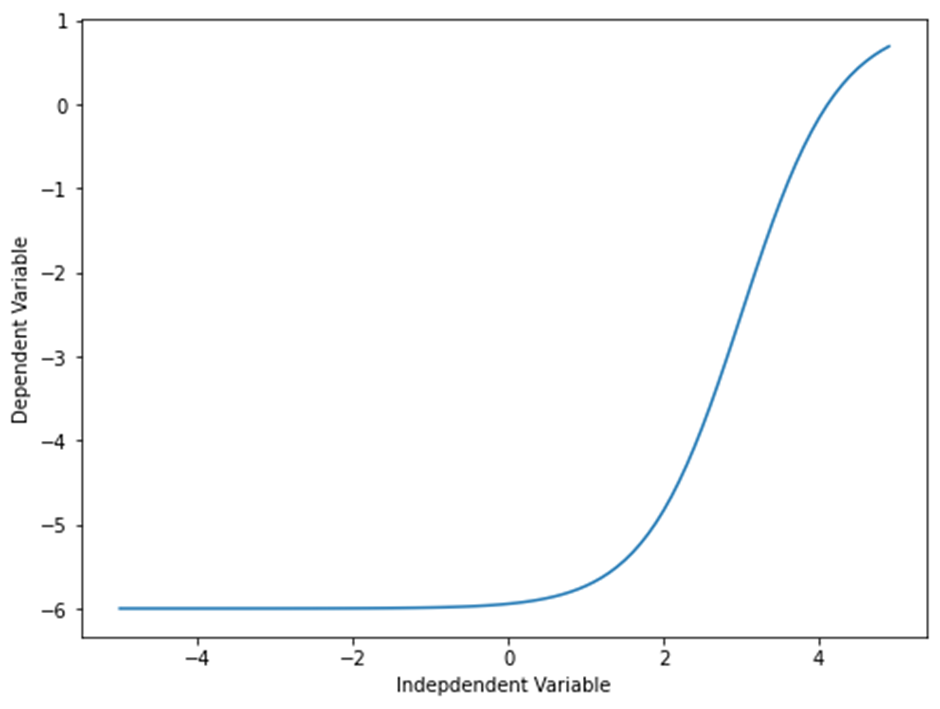
비선형 함수 활용 예시
import pandas as pd path='./china_gdp.csv' # 출처 : https://www.kaggle.com/code/ibrahimbahbah/non-linear-regression-tutorial/data df = pd.read_csv(path) df.head(10) # ‘Year’, ‘Value’가 열 이름이고 각각 연도, 소득 데이터를 가짐 df.shape # (55, 2), 55행 2열의 데이터 df.info() # 각 열은 int64, float64 자료형을 가지고 null값이 없다. df.describe() # 요약 확인 plt.figure(figsize=(8,6)) x_data, y_data = (df["Year"].values, df["Value"].values) # x_data, y_data에 ‘Year’ 값과 ‘Value’ 값을 각각 할당 plt.plot(x_data, y_data, 'ro') plt.ylabel('GDP') plt.xlabel('Year') plt.show() # 데이터의 그래프 출력
데이터의 그래프를 보면 지수 함수 그래프와 비슷하지만 중간에 상승되는 굴곡이 하나 더 보이는 점에서 로지스틱 함수의 특성과 유사하다.
데이터에 맞는 방정식 고안
Y^=1/1+eβ1(X−β2)
β1 : 커브의 급경사를 제어합니다.
β2 : x축의 커브를 슬라이드합니다.
데이터 방정식 함수
def sigmoid(x, Beta_1, Beta_2): y = 1 / (1 + np.exp(-Beta_1*(x-Beta_2))) return y데이터 방정식 파라미터 최적화
xdata =x_data-mean(x_data)/max(x_data)-mean(x_data) # x 정규화 ydata =y_data-mean(x_data)/max(y_data)-mean(x_data) # y 정규화모델링
from scipy.optimize import curve_fit # 비선형 최소 제곱을 사용하여 시그모이드 함수를 데이터에 맞추는 함수 popt, pcov = curve_fit(sigmoid, xdata, ydata) # 파라미터 출력 print(" beta_1 = %f, beta_2 = %f" % (popt[0], popt[1]))데이터 방정식과 데이터 그래프 출력
x = np.linspace(1960, 2015, 55) x = x/max(x) plt.figure(figsize=(8,5)) y = sigmoid(x, *popt) plt.plot(xdata, ydata, 'ro', label='data') plt.plot(x,y, linewidth=3.0, label='fit') plt.legend(loc='best') plt.ylabel('GDP') plt.xlabel('Year') plt.show()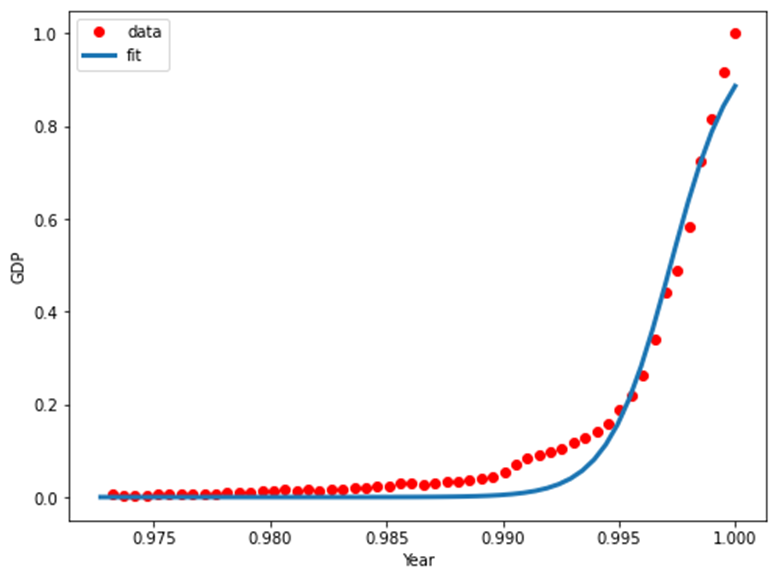
회귀 모델 평가
# train, test data 나누기 msk = np.random.rand(len(df)) < 0.8 # 0~1의 균일분포 표준정규분포 난수 생성 train_x = xdata[msk] test_x = xdata[~msk] train_y = ydata[msk] test_y = ydata[~msk] # 트레인 데이터를 이용해 모델링 popt, pcov = curve_fit(sigmoid, train_x, train_y) # 테스트 데이터를 이용해 예측 y_hat = sigmoid(test_x, *popt) # 평가 print("Mean absolute error: %.2f" % np.mean(np.absolute(y_hat - test_y))) print("Residual sum of squares (MSE): %.2f" % np.mean((y_hat - test_y) ** 2)) from sklearn.metrics import r2_score print("R2-score: %.2f" % r2_score(y_hat , test_y) ) # Mean absolute error : 0.03 # Residual sum od squares (MSE) : 0.00 # R2-score : 0.93'데이터 분석' 카테고리의 다른 글
[Python] 혼공 머신러닝 + 딥러닝 데이터 표준화의 중요성 (0) 2022.04.11 [Python] 혼공 머신러닝 + 딥러닝 샘플링 편향 (0) 2022.04.11 [python][ubuntu]'데이터 분석을 위한 Python, 3E' _ 1 (0) 2022.04.06